

Une tentative de bloquer une URL de phishing dans la plate-forme de stockage d’objets R2 de CloudFlare a rétroversé hier, déclenchant une panne répandue qui a fait baisser plusieurs services pendant près d’une heure.
CloudFlare R2 est un service de stockage d’objets similaire à Amazon S3, conçu pour le stockage de données évolutif, durable et à faible coût. Il offre des récupérations de données gratuites, une compatibilité S3, une réplication de données sur plusieurs emplacements et l’intégration de service CloudFlare.
La panne s’est produite hier lorsqu’un employé a répondu à un rapport d’abus sur une URL de phishing dans la plate-forme R2 de CloudFlare. Cependant, au lieu de bloquer le point de terminaison spécifique, l’employé a fait par erreur l’ensemble du service de passerelle R2.
« Au cours d’une réparation des abus de routine, des mesures ont été prises sur une plainte qui a inadverte les inadvertations au service de passerelle R2 au lieu du point de terminaison / seau spécifique associé au rapport » expliqué Cloudflare Dans son article post mortem.
« Il s’agissait d’une défaillance des contrôles de niveau multiple (avant tout) et de la formation des opérateurs. »
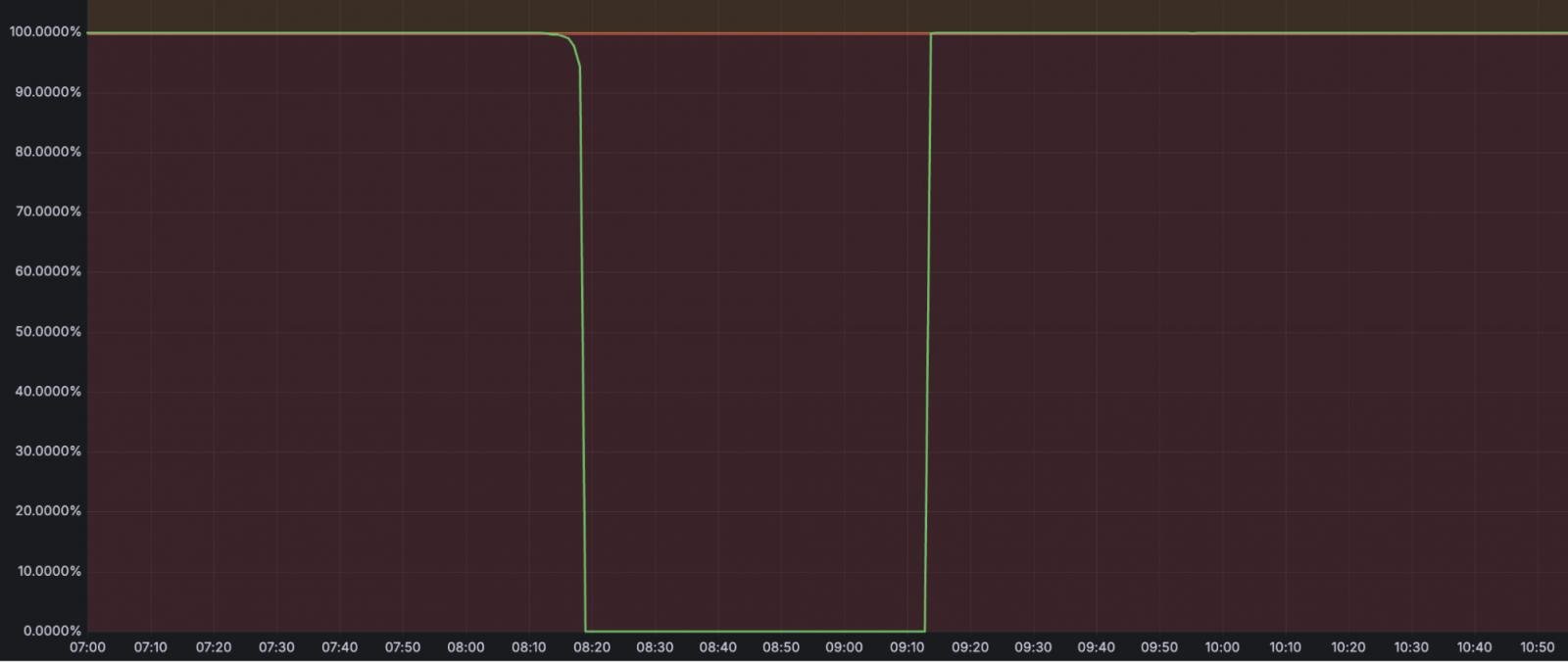
L’incident a duré 59 minutes, entre 08:10 et 09:09 UTC, et en dehors du stockage d’objets R2 lui-même, il a également affecté des services tels que:
- Flux – Échec à 100% dans les téléchargements de vidéos et la livraison de streaming.
- Images – Échec à 100% dans les téléchargements / téléchargements d’images.
- Réserve de cache – Échec à 100% des opérations, provoquant une augmentation des demandes d’origine.
- Vectoir – défaillance de 75% dans les requêtes, défaillance à 100% des opérations d’insertion, d’upsert et de suppression.
- Livraison de journaux – retards et perte de données: jusqu’à 13,6% de perte de données pour les journaux liés à R2, jusqu’à 4,5% de perte de données pour les travaux de livraison non R2.
- Auditeur de transparence clé – Échec à 100% dans les opérations de publication et de lecture de signature.
Il y avait également des services indirectement touchés qui ont connu des échecs partiels comme Objets durablesqui avait une augmentation du taux d’erreur de 0,09% en raison des reconnexions après la récupération, Purge de cachequi a vu une augmentation de 1,8% des erreurs (HTTP 5xx) et 10x pic de latence, et Travailleurs et pagescela a connu des défaillances de déploiement de 0,002%, affectant uniquement les projets avec R2 Bindings.
Source: Cloudflare
CloudFlare note que l’erreur humaine et l’absence de garanties telles que les vérifications de validation pour les actions à fort impact étaient essentielles à cet incident.
Le géant de l’Internet a maintenant mis en œuvre des correctifs immédiats tels que la suppression de la possibilité de désactiver les systèmes dans l’interface d’examen des abus et les restrictions de l’API Admin pour empêcher l’invalidité des services dans les comptes internes.
Les mesures supplémentaires à mettre en œuvre à l’avenir comprennent l’amélioration de l’approvisionnement des comptes, le contrôle d’accès plus stricte et un processus d’approbation à deux parties pour les actions à haut risque.
En novembre 2024, CloudFlare a connu une autre panne notable pendant 3,5 heures, entraînant la perte irréversible de 55% de tous les journaux du service.
Cet incident a été causé par des échecs en cascade dans les systèmes d’atténuation automatiques de CloudFlare déclenchés en poussant une mauvaise configuration vers un composant clé dans le pipeline de journalisation de l’entreprise.

